Advertisement
When your model finally performs well enough to impress you, the next question is: now what? That's when deployment enters the picture. A model that sits in your notebook doesn't help anyone. It needs a way to be accessed and used—preferably in real time and ideally by people who know nothing about Python. That's where Flask makes life easy. It lets you wrap your trained model in a lightweight web app without setting up a huge infrastructure. If you're comfortable with Python, you're already halfway there.
Flask is a micro web framework. That just means it keeps things simple. You don’t have to write unnecessary boilerplate or deal with a lot of configurations. It gives you the basic tools to get your app up and running, and you get to decide how big or small it becomes. For a single machine learning model that doesn’t need GPU acceleration or complex pipelines, Flask does the job just fine. You can handle requests, send responses, and plug in your model—all within a few lines of code.

It’s especially good if you want to test an idea fast. Instead of worrying about setting up a whole backend stack, you can keep things minimal and focus on getting your model to respond to inputs through an API. That means quicker feedback and less clutter.
Let’s break the process into a few clear parts so you’re not stuck piecing together different tutorials.
You can use any library you like—scikit-learn, TensorFlow, PyTorch. Once the model is trained, save it in a way that makes it easy to reload later.
Here’s an example with scikit-learn:
python
from sklearn.ensemble import RandomForestClassifier
import joblib
# Assume X_train and y_train are already prepared
model = RandomForestClassifier()
model.fit(X_train, y_train)
# Save the model
joblib.dump(model, 'model.pkl')
The key here is to make sure whatever you save is compatible with the environment where you’ll serve it. It also helps to write down the exact version of the libraries you used when training so you can reproduce the environment later or troubleshoot errors during deployment. Stick with Joblib or Pickle for simpler models. If you're using deep learning models, you'll probably go with .h5 or .pt formats.
You’ll now create a small server that can load the model and wait for input. Every time it receives a request, it processes it, runs it through the model, and returns a prediction.
Here’s a basic Flask setup:
python
from flask import Flask, request, jsonify
import joblib
import numpy as np
app = Flask(__name__)
model = joblib.load('model.pkl')
@app.route('/predict', methods=['POST'])
def predict():
data = request.get_json(force=True)
input_values = np.array(data['input']).reshape(1, -1)
prediction = model.predict(input_values)
return jsonify({'prediction': prediction.tolist()})
if __name__ == '__main__':
app.run(debug=True)
That’s it. This code sets up a single endpoint at /predict that takes JSON input and returns a prediction. Make sure the incoming data matches the format the model expects, or it will throw errors.
You’ll want to check if everything works locally before deploying it anywhere.
You can use curl, Postman, or even write a small script:
python
import requests
url = 'http://localhost:5000/predict'
data = {'input': [5.1, 3.5, 1.4, 0.2]}
response = requests.post(url, json=data)
print(response.json())
If the model loads correctly and your endpoint is receiving and processing input, you’ll get a response like:
json
{'prediction': [0]}
This means your Flask app is working as expected and can now be deployed beyond localhost.
Once everything is working locally, the next move is to make the app accessible to users or other systems. You can use services like Heroku, Render, or even a VPS with Gunicorn and Nginx.
Here’s how you’d run it with Gunicorn:
bash
gunicorn app:app
This makes the app more robust than Flask’s built-in development server. If you go with a platform like Heroku, the steps usually involve creating a requirements.txt, adding a Procfile, and pushing your code to a Git repo.
Example requirements.txt:
nginx
flask
scikit-learn
joblib
gunicorn
Example Procfile:
makefile
web: gunicorn app:app
Push this to Heroku, and your model will be live in just a few minutes.

Model mismatch: If the input format has changed even slightly from training, you’ll get unexpected results or errors. Always validate incoming data.
Scaling issues: Flask works for small projects. But if you’re expecting thousands of requests per second, you’ll need a stronger backend setup, like FastAPI or using a cloud function.
Security: Don’t expose your model’s logic or let people send raw input without validation. Always sanitize and check your data.
Version compatibility: If you trained your model with a specific version of scikit-learn, stick with that version in production. Otherwise, you might run into compatibility issues.
Deploying a machine learning model with Flask doesn’t have to be overwhelming. If you already know how your model behaves and what kind of input it expects, the rest is mostly setting up the right glue. Flask handles that glue well without forcing you to learn a completely new tool. It’s simple, readable, and flexible enough for most small to medium projects.
Once you get the hang of it, pushing a new model live becomes just another step in the process. And if your model needs to grow beyond Flask, you’ll already have the foundation in place. But for now, Flask is a great place to start. It's also a good way to understand how your model performs in real-world conditions beyond just test datasets and local predictions. Tay tuned for more helpful guides.
Advertisement

Dive into the strengths and weaknesses of open-source AI models and what they mean for innovation.

How the Python Global Interpreter Lock (GIL) works, how it affects threading and performance, and when Python multithreading is useful or limited
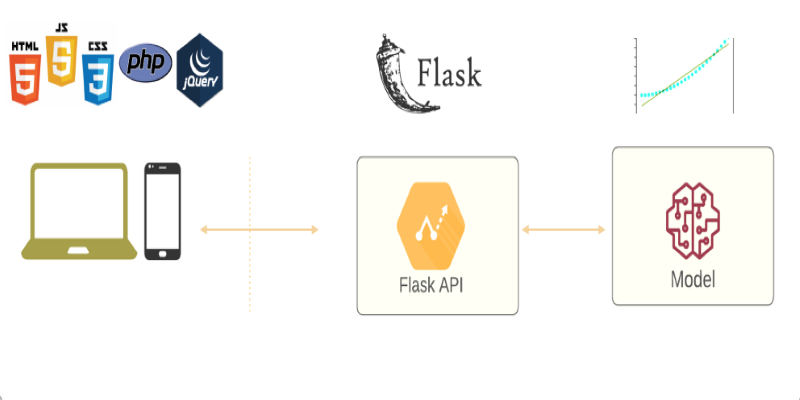
Learn how to deploy your machine learning model with Flask in 2025. Step-by-step guide on setting up Flask, testing your API, and making your model production-ready

Learn how to create effective charts using ggplot in Python. This guide covers syntax, setup, and examples for powerful data visualization using the plotnine library
Looking to process massive datasets efficiently? Discover how AWS EMR offers scalable, flexible solutions for big data processing with minimal setup and cost

Discover UiPath's latest update with smarter AI bots, easier bot design, improved integration, and powerful automation tools

From sorting files to predicting storage needs, see how AI helps manage and optimize your data storage without any effort.

Learn how to access GPT-4 on ChatGPT. Follow these steps to unlock AI features and boost your productivity.

How can AI help storytellers in filmmaking? Discover how LTX Studio uses AI to generate scenes from written descriptions, making the video creation process faster and more flexible for creators

Discover how ChatGPT can revolutionize your cooking routine by offering meal plans, recipe ideas, and even cooking tips based on what’s in your kitchen

In daily life, inductive arguments transform ideas, guide behavior, and enable intelligent choices grounded on noticed trends

Adobe plans to integrate generative AI tools from OpenAI and others to boost creative workflows and user productivity