Advertisement
If you've been dealing with massive datasets and your system keeps gasping for air, AWS EMR might be the tool that saves the day. It's built to process huge amounts of data across scalable clusters, and the best part is that you don't have to build everything from scratch. Amazon does the heavy lifting on setup, and you get to focus on the part that actually matters—analysis.
You can run frameworks like Apache Spark, Hive, and Hadoop without worrying about managing the environment. It’s all automated behind the scenes. And since it connects with other AWS services like S3 and DynamoDB, you won’t be stuck juggling different platforms. Let’s break down how it actually works and what makes it worth considering.
At its essence, AWS EMR is a managed platform for clusters. What that implies is you have a collection of machines (referred to as nodes), and each one of them serves a particular purpose. You can execute data-intensive applications by distributing the workload across several nodes. And you don't have to own or manage those machines—they're hosted on Amazon EC2 instances.
When you start an EMR cluster, you choose your framework (such as Spark or Hadoop), and AWS configures it for you. It allocates one node to control the cluster (the master node) and others to perform the actual processing (core and task nodes). When you have increased workload, you can scale up by adding extra nodes or scale down when you have less workload. That's where you save costs—you pay for only what you consume.
Since EMR integrates with Amazon S3, your input and output data can be stored separately from the cluster. So, even if your cluster shuts down, the data stays safe. Plus, you can connect it to tools like Amazon CloudWatch to monitor performance or step in if something goes wrong. Everything is managed through a console, which makes it easy to keep an eye on your jobs.

Plenty of tools out there help with data processing, but not all of them work well at scale. EMR does, and that’s why it's used by companies that process petabytes of data regularly. Here are a few things that make it stand out.
With EMR, there’s no need to plan far ahead. You can start with just a few nodes and grow as needed. If your job spikes overnight or dies down the next day, your cluster can adjust automatically. This elasticity matters when you're running time-sensitive tasks and can’t afford delays.
Instead of buying hardware or paying for unused time, EMR bills you by the second. You only pay for the computing and storage you actually use. You can also mix instance types—use spot instances to save money or on-demand instances when you need reliability. Either way, there's room to control your costs.
It doesn’t ask you to switch tools. If your team already uses Spark, Hive, or Presto, EMR supports them out of the box. You can also combine them in the same cluster. That means less friction and faster results.
Because EMR sits inside AWS, it plugs into other services smoothly. You can pull raw data from S3, run your processing jobs, and then write cleaned-up results back into Redshift or RDS. It keeps your pipeline within one system, which reduces bugs and makes it easier to manage.
To keep things simple, here’s how you’d go from nothing to a running cluster. First, you choose the framework you want to run. Most people go for Spark, Hive, or Hadoop, depending on what kind of job they’re handling. EMR offers prebuilt Amazon Machine Images (AMIs), so you won’t have to deal with setting things up manually.
Next comes the cluster configuration. You'll decide how big it needs to be—basically, how many instances you want for the master, core, and task nodes and what types they should be. Spot instances help lower costs, but at least one on-demand instance should handle the master role to avoid interruptions.
Once the setup is ready, you connect the cluster to your data. This could be stored in an S3 bucket, a relational database like RDS, or even streamed in through Kinesis. EMR can easily handle all of these sources.
Now it’s time to run the job. You can submit it using the console, a command line tool, or the API. If your work involves multiple stages—say extraction, transformation, and loading—you can break it into steps and monitor progress from the EMR dashboard.
When everything finishes, shut down the cluster so you’re not billed for idle time. Since your data stays in S3 or wherever you stored it, you won’t lose anything important once the cluster is off.

EMR isn’t for everyone. But when you’re working with terabytes or petabytes of data, and you need it processed quickly, it’s one of the most practical tools out there. It’s used in everything from ad targeting to fraud detection to genomics. And because it supports so many different tools, it works well with different teams—analysts, engineers, scientists—you name it.
If your workloads are bursty or seasonal, EMR's flexibility pays off. You don’t need a huge setup running all the time. Spin up a cluster, get your results, then shut it down. That’s one of the biggest reasons teams switch to EMR in the first place.
AWS EMR helps you handle big data without getting buried in setup or maintenance. It’s fast, scalable, and designed to work well with the tools you already use. You only pay for what you need, and the setup doesn’t require a full-time engineer to keep it running. If you’re dealing with huge datasets and don’t want to waste time or money managing infrastructure, EMR might just be your next best move.
Advertisement

Discover VR’s present and future: gaming, therapy, training and metaverse integration. VR trends for 2030.

Explore machine learning use cases and business benefits from marketing to cybersecurity.

Find out the 10 unique ways to use advanced data visualization with Matplotlib to make your charts more engaging, clear, and insightful. From heatmaps to radar charts, learn how to go beyond basic graphs and explore deep-er patterns in your data

Learn how artificial intelligence organizes random data, increases output, and drives efficiency throughout content management

Looking for the best Synthesia AI alternatives in 2025? Discover smart AI video tools that help you create videos with avatars, text-to-speech, and script automation faster and easier

Learn how to access GPT-4 on ChatGPT. Follow these steps to unlock AI features and boost your productivity.

Noom CEO details how AI-driven health technology delivers tailored health support, boosting engagement and improving outcomes
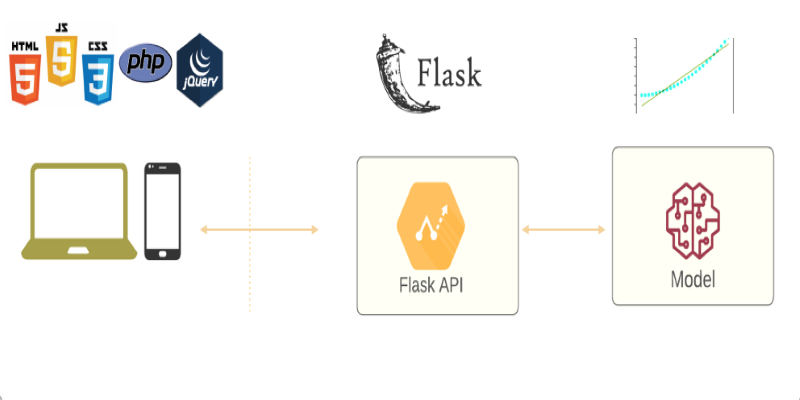
Learn how to deploy your machine learning model with Flask in 2025. Step-by-step guide on setting up Flask, testing your API, and making your model production-ready

What’s really going on inside a black box AI model? Discover how deep learning, abstraction, and randomness make AI powerful—but hard to explain

DataRobot's Feature Discovery runs inside Snowflake, offering more secure and scalable machine learning feature engineering

Discover reinforcement learning key concepts, training AI through feedback, and machine learning with rewards in action here

Discover UiPath's latest update with smarter AI bots, easier bot design, improved integration, and powerful automation tools