Advertisement
Reinforcement learning is a type of machine learning where agents interact with an environment to learn optimal behavior. It lets systems accomplish objectives through trial and error, guiding judgments. Agents' activities determine whether they get rewards or penalties. These signals enable their improvement over time. Self-driving cars, robotics, and game artificial intelligence all depend heavily on reinforcement learning.
Unlike supervised learning, it learns from experience rather than labeled data. Many businesses use it now for smart decisions and automation. Understanding the core concepts of reinforcement learning, such as reward-based learning and feedback-driven training, is crucial. Many practical uses find their basis in these concepts. This article provides a simplified overview of the fundamental ideas. You'll learn how agents work, what rewards mean, and where it's used today.

An agent making decisions within an environment is the essence of reinforcement learning. Every deed done alters the condition of the surroundings. The agent earns a reward or a punishment based on the new state. The aim is to maximize the total prizes over time. Policies defining agent behavior help to guide actions taken. Through many trials, the agent discovers which behaviors are ideal. Feedback helps improve its performance. No teacher exists; the agent finds trends on his own.
Exploitation is the choice of behavior one already knows to be successful. A balance between exploration and exploitation ensures effective learning. Episodes in reinforcement learning span a beginning and a conclusion. Rewards obtained during episodes direct the next actions. Agent learning improves throughout several episodes. We term this process policy improvement. Though it takes time, the model gets smarter with a training session. The approach reflects how people pick lessons from experience.
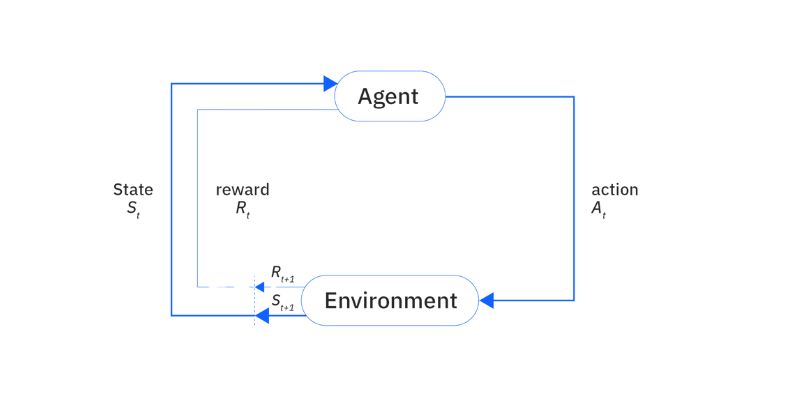
Several important words used in reinforcement learning help to define system behavior. An agent is the decision-maker within the surroundings. The environment the agent deals with is the planet. A state sums up the present state of affairs. Actions are decisions the agent has at hand. Every action results in a fresh condition and effect. A reward is feedback the agent gets back off from acting. It might turn out either good or bad.
A policy is the agent's method of choosing behavior. From every stage, the value function projects future benefits. In a given condition, a Q-value—or action-value—helps one assess the rewards for different actions. The episode spans a complete cycle from beginning to conclusion. Exploration is an agent trying novel behaviors. Exploitation bases choices on known knowledge. The calculation of rewards depends on the learning rate and discount factor.
Reinforcement learning comes in several forms based on how the agent learns. Positive reinforcement is rewarding excellent behavior. That motivates the agent to keep acting in such a manner. Negative reinforcement involves removing an unpleasant condition in response to desired behavior, encouraging it to happen again. It lets the agent steer clear of poor decisions. Model-based learning forecasts results using an environmental model. Before deciding on one, the agent acts out several possibilities. Model-free learning does not rely on internal models of the environment.
Whereas policy-based methods directly change policies to identify the best options, value-based methods like Q-learning employ a value function to guide actions. Actor-critic approaches learn effectively using both value and policy. Depending on intricacy, each type is suited to different tasks. Simple problems let model-free learning shine. Model-based approaches are superior for complicated systems. Understanding these kinds guides one to select the appropriate learning strategy.
Many sectors of today apply reinforcement learning. Robotics teaches machines to grasp or walk objects. Robots learn by trial and error how to fit in new surroundings. Reinforcement learning enables the creation of advanced decision-making agents in games. AlphaGo and other games employ this approach to perfect strategy. Self-driving cars depend on it to negotiate roadways, prevent collisions, and improve over time. In healthcare, it supports robotic procedures and treatment planning. Systems learn patient reactions to increase results.
Reinforcement learning helps Finance control portfolios and forecast stock movements. It responds fast to evolving patterns. Advertising chooses the best commercials for every audience to increase interaction. Smart energy systems exploit it to maximize power usage. AI bots can provide improved responses, even in customer support scenarios. Feedback-based learning lets machines complete jobs humans find difficult to specify or program.
Reinforcement learning depends on powerful algorithms to guide agents. Q-learning is one popular technique. It updates action values based on experience and stores them in a Q-table. The agent chooses among actions the ones with the most value. Deep Q Networks (DQN) mix deep learning with Q-learning. It enables agents to utilize neural networks to manage challenging surroundings.
SARSA is another method that updates values based on the action taken, emphasizing real-world experience. Unlike Q-learning, it emphasizes real-world experience above ideal results. Policy Gradient techniques modify the policy directly rather than via value functions. These help in constant activity environments. For stable learning, Actor-Critic blends value updates with policy changes. It is based on two models: value and policy. Different algorithms suit different environments and problems. Simpler tasks are better suited for basic methods.
Though it presents difficulties, reinforcement learning has several advantages. Training requires time and usually numerous sessions. Sometimes, agents do not pick up appropriate policies. Agents find it difficult to discern which acts were correct from sparse rewards. Environments could not be easily replicable or stable. Exploration can result in bad decisions that compromise performance.
Another problem is computation expense. Large state or action spaces require significant computational resources. One also runs the danger of overfitting to training settings. Moving to real-world duties, the agent might not be successful. In jobs like driving or healthcare, safety comes first. Bad decisions could have major consequences. Some techniques are opaque, which makes action explanations difficult. Meta-learning and transfer learning, among other tools, save training time.
Reinforcement learning lets robots learn by mistake to enhance actions gradually. In robotics, healthcare, and gaming, it is vital. Widely utilized algorithms are Q-learning and DQN. Despite difficulties, development keeps on. A solid understanding of core reinforcement learning concepts ensures the development of smarter AI systems, training AI through feedback and machine learning with rewards. Many of the next developments will be driven by reinforcement learning. Feedback transforms into learning in powerful and adaptable ways. It will proliferate in daily life and in sectors over time.
Advertisement
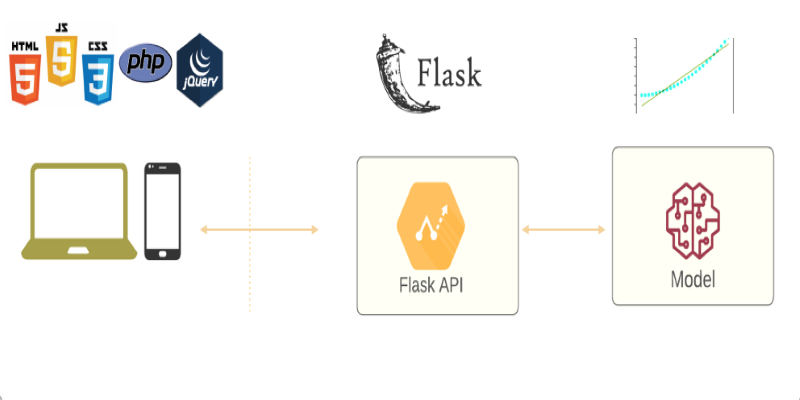
Learn how to deploy your machine learning model with Flask in 2025. Step-by-step guide on setting up Flask, testing your API, and making your model production-ready

How can AI help storytellers in filmmaking? Discover how LTX Studio uses AI to generate scenes from written descriptions, making the video creation process faster and more flexible for creators

What’s really going on inside a black box AI model? Discover how deep learning, abstraction, and randomness make AI powerful—but hard to explain

Learn how artificial intelligence organizes random data, increases output, and drives efficiency throughout content management

Confused by AI buzzwords? This glossary breaks down 29 essential terms—like LLMs, embeddings, and transformers—into plain language anyone can understand

From sorting files to predicting storage needs, see how AI helps manage and optimize your data storage without any effort.

Encountering errors in ChatGPT? Learn how to fix common issues like "not responding," "network errors," and more with these easy-to-follow solutions

Explore the most reliable data science platforms in 2025. From notebooks to automated modeling, find the best tools for data science across all skill levels

Dive into the strengths and weaknesses of open-source AI models and what they mean for innovation.

Discover reinforcement learning key concepts, training AI through feedback, and machine learning with rewards in action here

Explore machine learning use cases and business benefits from marketing to cybersecurity.

Learn how to access GPT-4 on ChatGPT. Follow these steps to unlock AI features and boost your productivity.